
Stoppschilder sehen in vielen Ländern ähnlich aus – rot, achteckig, mit dem Wort „STOP“ in der Mitte. Allerdings gibt es Ausnahmen: In Japan sind die Schilder dreieckig, in China wird das Wort „STOP“ durch ein Schriftzeichen ersetzt, in Algerien durch eine gehobene Hand. Ortsfremde Fahrer haben mit diesen kleinen Unterschieden kein Problem. Spätestens nach der ersten Kreuzung wissen sie, wie das lokale Stoppschild aussieht. Die Künstliche Intelligenz (KI) in einem autonomen Fahrzeug benötigt hingegen ein komplett neues Training, um den kleinen Unterschied verarbeiten zu können.
Diese immer neuen Lektionen benötigen viel Zeit, verursachen hohe Kosten und bremsen so das autonome Fahren insgesamt aus. Deshalb setzt die Automobilindustrie jetzt zum gemeinsamen Schritt nach vorne an: Im Projekt „KI Delta Learning“ sollen Wege gefunden werden, autonomen Fahrzeugen selektiv etwas Neues beizubringen. Um beim Beispiel zu bleiben: Man will dem Autopiloten in Zukunft nur noch sagen müssen: „Alles bleibt gleich, bis auf das Stoppschild.“

Kooperation von großen Partnern
Wie bedeutend diese Aufgabe ist, zeigt schon die Teilnehmerliste des Großprojektes, das vom Bundeswirtschaftsministerium gefördert wird: Partner des Projektes sind neben Porsche Engineering auch BMW, CARIAD und Mercedes-Benz sowie Großzulieferer wie Bosch und neun Hochschulen, darunter die TU München und die Universität Stuttgart. „Es geht darum, den Aufwand zu reduzieren, um von einer Fahrsituation auf eine andere schließen zu können – ohne sie extra zu trainieren“, erklärt Dr. Joachim Schaper, Leiter KI und Big Data bei Porsche Engineering. „Die Kooperation ist nötig, weil derzeit kein Anbieter allein diese Herausforderung bewältigen kann.“ Das Projekt ist Teil der „KI Familie“, einer Leitinitiative des Verbandes der Automobilindustrie, mit der das vernetzte und autonome Fahren vorangebracht werden soll.
Rund 100 Personen bei insgesamt 18 Partnern forschen seit Januar 2020 an „KI Delta Learning“. Es finden Workshops statt, bei denen sich die Experten darüber austauschen, welche Ansätze erfolgversprechend sind – und welche sich als Sackgasse erwiesen haben. „Wir hoffen, am Ende einen Katalog von Methoden liefern zu können, mit denen sich der Wissenstransfer in der Künstlichen Intelligenz ermöglichen lässt“, sagt Mohsen Sefati, Experte für autonomes Fahren bei Mercedes-Benz und Leiter des Projektes.
Tatsächlich verbirgt sich hinter dem Stoppschild-Beispiel eine grundsätzliche Schwäche aller neuronalen Netze, die in autonomen Fahrzeugen das Verkehrsgeschehen interpretieren. Sie ähneln vom Aufbau her dem menschlichen Hirn, unterscheiden sich jedoch in einigen entscheidenden Punkten: So können sich neuronale Netze ihre Fähigkeiten nur auf einmal aneignen, typischerweise in einer einzigen großen Trainings-Session.
Großer Aufwand durch Domänenwechsel
Selbst triviale Veränderungen können in der Entwicklung von Autopiloten großen Aufwand verursachen. Ein Beispiel: In vielen autonomen Testfahrzeugen wurden bisher Kameras mit einer Auflösung von zwei Megapixeln eingebaut. Werden sie jetzt durch bessere Modelle mit acht Megapixeln ersetzt, ändert sich im Prinzip kaum etwas. Ein Baum sieht noch immer wie ein Baum aus, nur dass er durch mehr Pixel repräsentiert wird. Die KI benötigt trotzdem wieder Millionen von Schnappschüssen aus dem Verkehr, um die Objekte in der höheren Auflösung zu erkennen. Das Gleiche gilt, wenn ein Kamera- oder Radarsensor am Fahrzeug nur leicht anders positioniert wird. Danach ist ebenfalls ein komplettes Neutraining angesagt.
„Es geht darum, den Aufwand zu reduzieren, um von einer Fahrsituation auf eine andere schließen zu können – ohne sie extra zu trainieren.“ Dr. Joachim Schaper, Leiter KI und Big Data bei Porsche Engineering
Fachleute nennen so etwas einen Domänenwechsel: Statt rechts wird links gefahren, statt strahlendem Sonnenschein tobt ein Schneesturm. Menschlichen Fahrern fällt es in der Regel leicht, sich anzupassen. Sie erkennen intuitiv, was sich ändert, und übertragen ihr Wissen auf die veränderte Situation. Neuronale Netze können das noch nicht. Ein System, das zum Beispiel mit Schönwetterfahrten trainiert wurde, ist bei Regen verwirrt, weil es seine Umwelt aufgrund der Reflexionen nicht mehr erkennt. Das gilt ebenso für unbekannte Wetterbedingungen, für den Wechsel von Links- zu Rechtsverkehr oder für unterschiedliche Ampelformen. Und tauchen im Verkehr gänzlich neue Objekte wie E-Scooter auf, muss der Autopilot damit zunächst vertraut gemacht werden.
Ziel des Projektes: nur das „Delta“ lernen
In all diesen Fällen ist es bislang nicht möglich, dem Algorithmus nur die Veränderung beizubringen, also das, was in der Wissenschaft das „Delta“ genannt wird. Um sich in der neuen Domäne zurechtzufinden, braucht er wieder einen kompletten Datensatz, in dem die Modifikation vorkommt. Es ist, als müsste ein Schüler bei jeder neuen Vokabel das komplette Wörterbuch durcharbeiten.
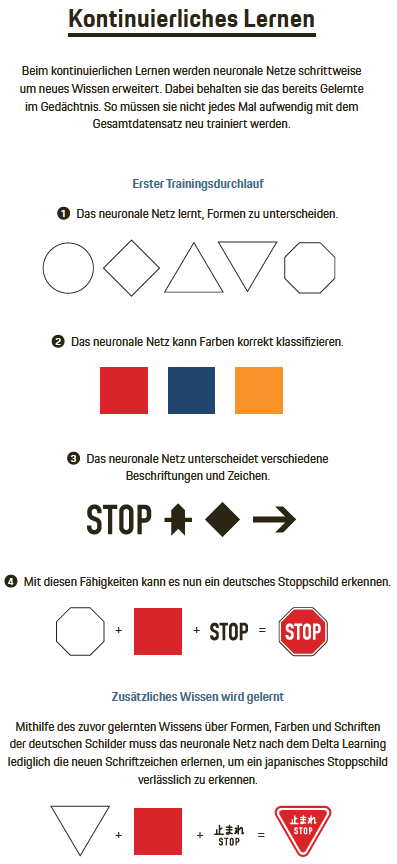
Diese Art des Lernens verschlingt enorme Ressourcen. „Um einen Autopiloten zu trainieren, sind heute 70.000 Grafikprozessor-Stunden nötig“, erklärt Tobias Kalb, Doktorand und für Porsche Engineering am Projekt „KI Delta Learning“ beteiligt. In der Praxis werden zwar zahlreiche Graphics Processing Units (GPUs) parallel genutzt, um neuronale Netze zu trainieren, dennoch bleibt der Aufwand erheblich. Hinzu kommt, dass ein neuronales Netz kommentierte Bilder braucht, also Aufnahmen aus dem realen Verkehrsgeschehen, in denen wichtige Elemente markiert sind, wie zum Beispiel andere Fahrzeuge, Fahrspurmarkierungen oder Leitplanken. Führt ein Mensch diese Arbeit von Hand durch, dauert es eine Stunde oder mehr, bis eine Momentaufnahme aus dem Stadtverkehr annotiert ist. Jeder Fußgänger, jeder einzelne Zebrastreifen, jedes Baustellenhütchen muss im Bild markiert werden. Dieses sogenannte Labeling lässt sich zwar teilweise automatisieren, dafür werden aber große Rechenkapazitäten gebraucht.

Hinzu kommt, dass ein neuronales Netz mitunter Gelerntes wieder vergisst, wenn es sich an eine neue Domäne anpassen soll. „Es fehlt ein echtes Gedächtnis“, erklärt Kalb. Er selbst hat diesen Effekt erlebt, als er ein KI-Modul verwendete, das mit US-amerikanischen Verkehrsszenen trainiert wurde. Es hatte viele Bilder von leeren Highways und weiten Horizonten gesehen und konnte den Himmel zuverlässig identifizieren. Als Kalb das Modell zusätzlich mit einem deutschen Datensatz trainierte, trat ein Problem auf. Nach dem zweiten Durchlauf bekam das neuronale Netz Schwierigkeiten, den Himmel in den amerikanischen Aufnahmen zu identifizieren. Auf dem deutschen Bildmaterial war es nämlich oft bewölkt oder Gebäude versperrten die Aussicht.
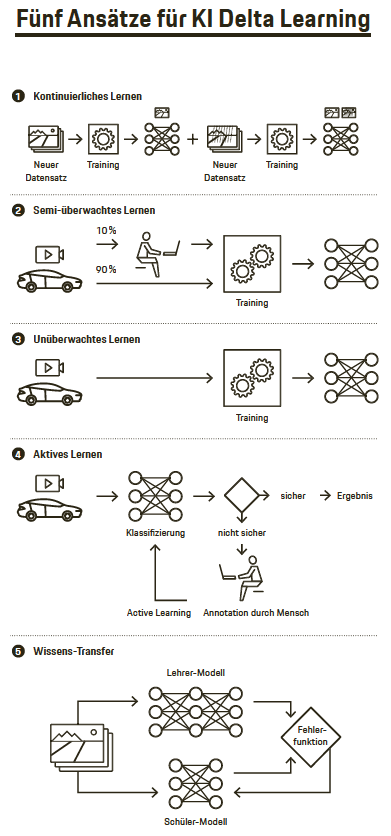
- Beim kontinuierlichen Lernen werden Algorithmen entwickelt, die sich ohne Wissensverlust um neues Wissen erweitern lassen – ohne dass der Gesamtdatensatz neu trainieren werden muss. Im Unterschied zu herkömmlichen Verfahren müssen zur Trainingszeit nicht alle Daten vorliegen. Stattdessen können später weitere Daten schrittweise ins Training aufgenommen werden. So kann ein neuronales Netz beispielsweise lernen, ein japanisches Stoppschild zu erkennen, ohne dass es das deutsche Stoppschild vergisst.
- Beim semi-überwachten Lernen sind nur für einen kleinen Teil der Daten Labels vorhanden, mit denen man sie in eine Kategorie einteilen kann. Der Algorithmus trainiert darum mit ungelabelten und gelabelten Daten. So kann man zum Beispiel mit einem Modell, das mit gelabelten Daten trainiert wurde, Vorhersagen für einen Teil der ungelabelten Daten machen. Diese Vorhersagen lassen sich dann in die Trainingsdaten aufnehmen, um mit diesem erweiterten Datensatz ein weiteres Modell zu trainieren.
- Beim unüberwachten Lernen (Unsupervised Learning) lernt eine Künstliche Intelligenz mithilfe von Daten, die zuvor nicht manuell in Kategorien eingeteilt worden sind. So lassen sich Daten ohne Unterstützung durch den Menschen clustern, Merkmale aus ihnen extrahieren oder eine neue komprimierte Repräsentation der Eingabedaten lernen. Im Projekt „KI Delta Learning“ wird unüberwachtes Lernen einerseits eingesetzt, um neuronale Netze zu initialisieren und die Anzahl der annotierten Trainingsdaten zu reduzieren. Andererseits kann man damit ein bereits trainiertes Netz auf eine neue Domäne anpassen, indem man versucht, eine einheitliche Repräsentation der Daten zu lernen. Wenn man beispielsweise einen Domänenwechsel von Tag- zu Nacht-Aufnahmen macht, sollten die Merkmale, die das Modell für ein Auto bei Tag gelernt hat, genauso bei Nacht anzuwenden sein. Sie sollten also im Idealfall Domänen-invariant sein.
- Beim aktiven Lernen wählen Algorithmen während der Trainingszeit die Trainingsdaten für ein neuronales Netz selbst aus – zum Beispiel diejenigen Situationen, die bisher nicht vorgekommen sind. Bei der Auswahl stützt man sich unter anderem auf Unsicherheitsmaße, die abschätzen, wie sicher eine Vorhersage des neuronalen Netzes ist. Durch aktives Lernen kann man beispielsweise den Aufwand für das manuelle Annotieren von Videobildern verringern, weil nur noch diejenigen Trainingsdaten bearbeitet werden müssen, die später für das Lernen essenziell sind.
- Beim Wissentransfer (Knowledge Distillation) geht es darum, Wissen zwischen neuronalen Netzen zu transferieren – meist von einem komplexeren Modell (Lehrer)zu einem kleineren Modell (Schüler). Komplexere Modelle haben meist eine größere Wissenskapazität und erreichen dadurch höhere Vorhersage-Genauigkeiten. Durch Knowledge Distillation wird das im komplexen Netz enthaltene Wissen in einem kleineren Netz komprimiert, wobei nur geringe Genauigkeitseinbußen zu erwarten sind. Knowledge Distillation wird auch im kontinuierlichen Lernen eingesetzt, um den Verlust von Wissen zu verringern.
„Bisher wird in solchen Fällen das Modell mit beiden Datensätzen neu trainiert“, erklärt Kalb. Doch das ist aufwendig und stößt irgendwann an Grenzen, etwa wenn die Datensätze zu umfangreich werden, um sie noch abzuspeichern. Kalb fand durch Versuche eine bessere Lösung: „Manchmal reichen sehr repräsentative Bilder aus, um das Wissen aufzufrischen.“ Anstatt dem Modell noch einmal komplett alle amerikanischen und deutschen Straßenszenen zu zeigen, wählte er zum Beispiel ein paar Dutzend Bilder mit besonders typischem HighwayFernblick aus. Das genügte schon, um den Algorithmus daran zu erinnern, wie der Himmel aussieht.
Zwei KIs bilden sich gegenseitig aus
Genau solche Optimierungsmöglichkeiten sollen im Rahmen von „KI Delta Learning“ gefunden werden. Für insgesamt sechs Anwendungsbereiche suchen die Projektpartner nach Methoden, um die jeweilige KI schnell und einfach weiterzubilden. Dazu gehört unter anderem ein Wechsel in der Sensortechnik oder die Anpassung an unbekannte Wetterverhältnisse. Bewährte Lösungen teilen die am Projekt beteiligten Organi sationen untereinander.
Ein weiterer vielversprechender Ansatz besteht darin, dass sich zwei WahrnehmungsKIs gegenseitig ausbilden. Zunächst wird dafür ein LehrerModell aufgebaut: Es erhält Trainingsdaten, in denen eine Klasse von Ob jekten markiert ist, zum Beispiel Schilder. Eine zweite KI, das SchülerModell, erhält ebenfalls einen Datensatz, in ihm sind jedoch andere Dinge markiert – Bäume, Fahrzeuge, Straßen. Dann beginnt der Unterricht: Das LehrerSystem vermittelt dem Schüler sein Wissen, während er neue Konzepte lernt. Es hilft ihm also dabei, Schilder zu erkennen. Danach wird der Schüler wiederum zum Lehrer für das nächste System. Diese Methode, „Knowledge Distillation“, könnte den OEMs viel Zeit bei der Lokalisierung ihrer Fahrzeuge ersparen. Soll ein Modell in einem neuen Markt eingeführt werden, muss beim Training des Autopiloten lediglich ein anderes LehrerModell für die regionalen Schilder verwendet werden – alles andere kann gleich bleiben.
„Die Lösung wird in einer Kombination von Verfahren liegen“
Vieles, was die Forscher derzeit testen, ist noch experi mentell. Mit welcher Methode sich ein neuronales Netz schlussendlich am besten an neue Domänen anpassen lässt, kann man noch nicht absehen. „Die Lösung wird in einer geschickten Kombination mehrerer Verfahren liegen“, erwartet Experte Kalb. Nach einem Jahr Projektarbeit sind die Beteiligten optimistisch. „Wir haben gute Fortschritte gemacht“, sagt Projektleiter Sefati von MercedesBenz. Er erwartet, erste Metho den zum KI Delta Learning vorweisen zu können, wenn das Projekt Ende 2022 ausläuft. Das könnte enorme Vorteile für die gesamte Automobilindustrie bringen. „Es gibt hohe Einsparpotenziale bei gleichzeitiger Steigerung der Qualität, wenn die Trainingskette stark automatisiert wird“, erklärt KI-Fachmann Schaper. Er schätzt, dass sich der menschliche Arbeitseinsatz bei der Entwicklung autonomer Fahrzeuge durch KI Delta Learning halbieren lässt.
Die KI Projektfamilie

KI Wissen
Entwicklung von Methoden für die Einbindung von Wissen in maschinelles Lernen.
KI Delta Learning
Entwicklung von Methoden und Werkzeugen zur effizienten Erweiterung und Transformation vorhandener KIModule autonomer Fahr zeuge auf die Herausforde rungen neuer Domänen oder komplexerer Szenarien.
KI Absicherung
Methoden und Maßnahmen zur Absicherung von KI basierten Wahrnehmungs funktionen für das automatisierte Fahren.
KI Data Tooling
Prozesse, Methoden, Tools zur effizienten und syste matischen Generierung und Veredelung von Trainings, Test, Validierungs und Absicherungs-Daten für KI.
Zusammengefasst
Bei einem Wechsel der Umgebung oder der Sensorik müssen neuronale Netze in Fahrzeugen heute immer wieder von Grund auf neu trainiert werden. Das Projekt „KI Delta Learning“ hat das Ziel, ihnen nach einem solchen Domänenwechsel in Zukunft nur noch den Unterschied beizubringen und so den Aufwand erheblich zu reduzieren
Info
Text: Constantin Gillies
Text erstmals erschienen im Porsche Engineering Magazin, Ausgabe 2/2021.




.jpeg/jcr:content/Doln%E2%80%9D%20V%E2%80%9Dtkovice,%20Boris%20Renner%20(1).jpeg)